Abstract
Non-verbal behavior is essential for embodied agents like social robots, virtual avatars, and digital humans. Existing behavior authoring approaches including keyframe animation and motion capture are too expensive to use when there are numerous utterances requiring gestures. Automatic generation methods show promising results, but their output quality is not satisfactory yet, and it is hard to modify outputs as a gesture designer wants. We introduce a new gesture generation toolkit, named SGToolkit, which gives a higher quality output than automatic methods and is more efficient than manual authoring. For the toolkit, we propose a neural generative model that synthesizes gestures from speech and accommodates fine-level pose controls and coarse-level style controls from users. The user study with 24 participants showed that the toolkit is favorable over manual authoring, and the generated gestures were also human-like and appropriate to input speech. The SGToolkit is platform agnostic, and the code is available at this https URL.
Why do we need new approach to generate gestures for speeches?
It is not trivial to make plausible non-verbal behavior for the agents. Typical ways to realize social behaviors are keyframe animation by artists or capturing human actors’ motion. Both methods give high-quality motions but there is a scalability issue due to their high production cost. Experienced animation artists are needed for the keyframe animation, and the motion capture method requires expensive capturing devices and skilled actors. There is a need for a cheaper solution.
The cheapest way to generate social behavior is automatic generation; it does not require a human effort at the production time. There are two automatic gesture generation toolkits—Virtual Humans Toolkit from USC and NAOqi from SoftBank Robotics; however, both toolkits are not widely used because they are dependant on a specific platform and heavily relies on pre-described word–gesture association rules. Also, the gesture quality of the automatic gesture generation toolkits is not high enough, showing repetitive and monotonic motion and unnatural transitions between gestures. Recent data-driven gesture generation studies improved gesture qualities, but are still far behind human-level gestures. Another limitation of the data-driven gesture generation is that it cannot imply a designer’s intention. Even if generated gestures are as natural as human gestures, they might not be what a designer wants.
Concept
The key idea of the new gesture generation toolkit is combining automatic gesture generation and manual controls. The below figure shows the workflow of the proposed toolkit. The toolkit first generates gestures from speech automatically, and then users add control elements to refine the gestures. The toolkit provides fine-level pose control and coarse-level style control elements.
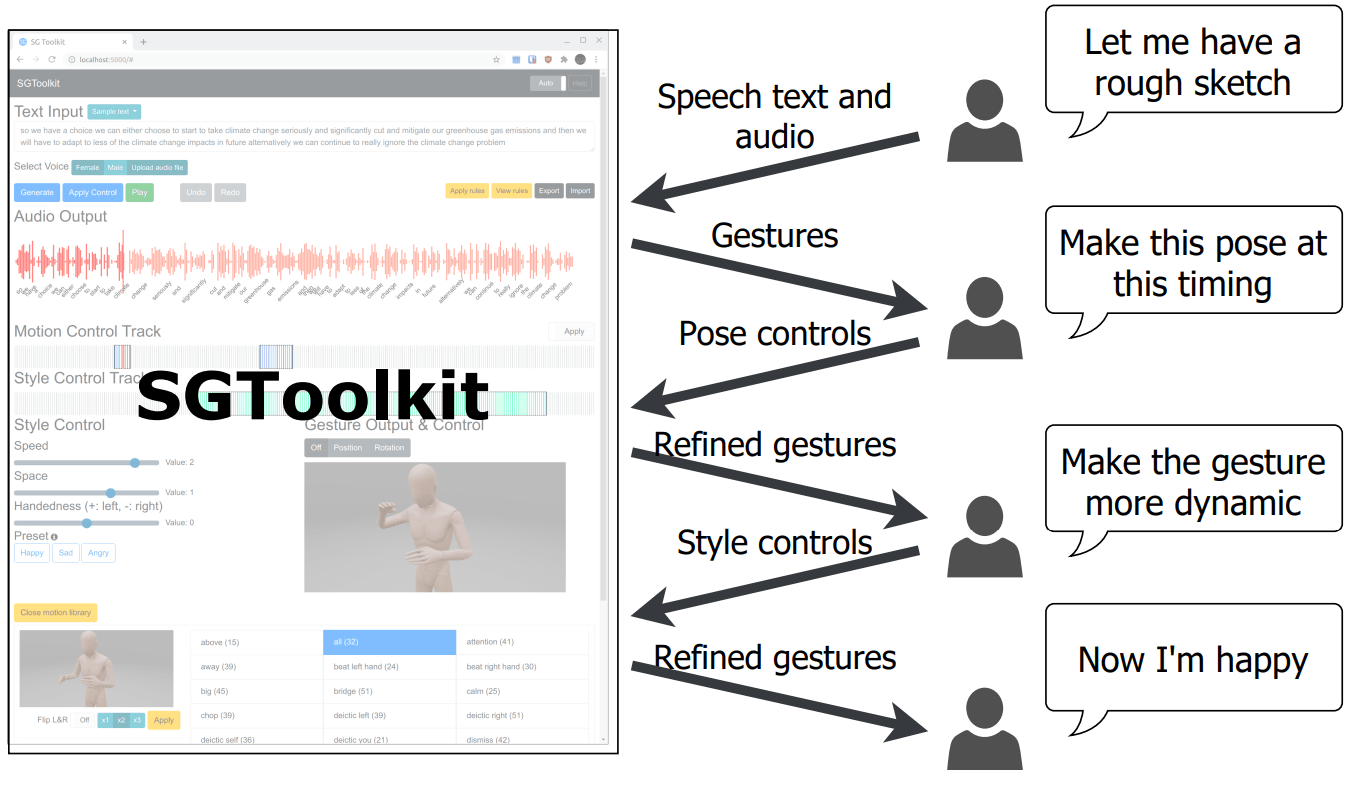
For more details of the gesuture generation and evaluation, please see our paper.
Resources
My contributions
I participated in
- expert interview
- interface design and impelemtation
- user study design