이 글은 Virginia Braun, Victoria Clarke의 Thematic Analysis: A Practical Guide 책을 읽고 그 내용을 정리한 글이다. 이 책은 크게 두 부분으로 나누어진다. 첫 번째 파트가 실전에 대한 이야기인데 이 글에서는 이 파트만 다룬다. Thematic Analysis(TA)를 해보고 싶은데 어떻게 해야 하는지 모르겠거나 대체 내가 하고 있는 것이 TA인지 헷갈리는 사람들에게 도움이 될 것이라 생각 한다.
위 책을 읽게 된 경위는 다음과 같다. 가끔 정성연구를 한 HCI 논문에서 TA에 대한 레퍼런스를 보게 되면 대부분 Using thematic analysis in psychology 논문을 인용한다. 이 논문을 읽어봐야겠다는 생각을 가지고 있었다. 그러던 차에, 이 논문의 저자들이 쓴 책이 Thematic Analysis: A Practical Guide라는 책을 알게 되었다. 이 책이라면 TA를 제대로 공부해 볼 수 있겠다는 생각에 설레이는 마음으로 구매를 해서 읽게 되었다.
이 책에서는 크게 6개로 TA의 세부 단계를 나누어 설명한다. 이 글에서는 TA의 대략적인 개념과 각 단계에 대한 내용을 간략하게 설명 하겠다.
- Familiarization
- Coding
- Generating initial themes
- Developing and reviewing themes
- Refining, defining and naming themes
- Writing
Thematic Analysis란
Thematic Analysis (TA)는 정량 분석을 하는 하나의 방법이다. 정량 데이터들에서 패턴을 개발하고, 분석하고, 찾아내는데 그 과정에서 ‘코딩’이나 ‘테마 개발’과 같은 시스템적인 접근 방식을 사용하는 것이다. 이렇게 이야기 하면 복잡한 방법론이라고 생각이 들 수 있지만 알고 보면 우리가 흔히 생각하는 자료 분석과 크게 다르지 않다. TA가 활용 될 수 있는 예를 들어보자. ‘부모들이 아이들을 양육 하면서 겪는 문제는 무엇일까?’하는 질문에서 시작해서 부모들을 인터뷰 한 자료가 있다고 해보자. 이 인터뷰 자료들로 부터 부모들이 겪는 문제들을 찾아내고 그 원인을 분석하는 방법으로서 TA가 활용 될 수 있다.
주의 해야 할 것은 TA는 방법론(methodology)이 아니라 방법(method)이라는 것이다. 방법론은 구체적으로 과정이 정해져 있는 것을 의미하지만 방법은 목적만 정해져 있을 뿐 그 과정은 비교적 다양할 수 있다. 이러한 관점에서 저자들은 그들이 추구하는 TA를 reflexive TA 라 이야기 한다. Reflexivity라는 것은 무엇인가? 영어 사전에 검색해 보면 ‘재귀’라는 뜻이 먼저 나오는데 그런 의미는 아니고 여기서는 ‘성찰’의 뜻으로 쓰인다. 책에 따르면 reflexivity는 연구자의 상황과 배경이 연구 과정에서 연구 대상자에게 어떻게 영향을 미치며 최종적으로는 결과에 어떻게 영향을 미칠 수 있는지 계속 생각하고 고려하는 자세를 이야기 한다. 구체적으로는 연구 과정에서의 가정, 기대, 선택, 그리고 행동 등을 주기적으로 돌아보는 것이다. 끊임 없는 스스로에 대한 성찰이 필요한 것이다.
이렇게 이야기 하면 reflexivity가 연구의 객관성을 유지하기 위한 것이라고 생각 할 수도 있지만 그렇지는 않다. 이 책을 읽으면서 새롭게 배운 것 중 하나인데, TA는 주관적일 수 밖에 없고 그것이 TA의 한계가 아니라 오히려 TA의 핵심이라는 것이다. 연구가 주관적이면 편향적일 수 밖에 없지 않을까 하는 생각을 할 수 있다. 하지만 그 편향성이 나쁜것이 아니라는 이야기를 이 책은 한다. 이건 우리가 ‘지식’의 정체를 어떻게 정의하는지와 관련된 이야기다. 흔히들 절대 참인 지식이 존재하고 그것을 연구자가 찾아내는 것이라고 생각 한다. 자연과학은 그럴 수 있지만 적어도 TA에서는 다르게 생각 한다. TA는 자연에 존재하는 지식을 찾아내는 것이 아니라 연구자가 지식을 생산하는 것이라는 관점을 가지고 있다. 지식의 존재론 (ontology)과 인식론 (epistemology)에 대한 이야기인데 이 글에서는 여기까지만 이야기 하겠다. 이제 각 단계에 대해서 좀 더 자세히 알아보자.
Familiarization: 데이터와 친해지기
이 책에서는 데이터를 모으는 방법이나 과정에 대해서는 거의 이야기 하지 않는다. TA 이름에서 볼 수 있듯이 분석에 대한 내용이기 때문이다. 정량 데이터를 모으는 방법은 상당히 많고 다양하다. 데이터 수집에 대해서 잘 나와있는 책을 추천 하자면 Research Methods in Human-Computer Interaction, 디자인 방법론 불면의 법칙 100가지 를 추천한다. 어쨌든 데이터는 정량 데이터가 존재하는 상황에서 부터 시작한다.
Familiarization은 세 가지 각기 다른 행위로 나누어진다. 첫 행위는 몰입 (immersion) 단계이다. 여기에서는 데이터를 계속 보면서 이해 하는 것이 중요하다. 만약 데이터가 모두 사라지더라도 대략적으로 어떤 데이터들이 있었는지 복기 할 수 있을 정도로 데이터를 체화 해야 한다. 두 번째 부분은 비판적으로 (critically) 데이터를 바라보는 것이다. 몰입과는 조금 반대되는 행위이다. 단순히 데이터를 암기하는 것이 아니라 왜 이런 데이터가 나오게 되었는지 이해하는 과정이다. 비판 과정에서 물어볼 수 있는 질문들은 다음과 같다. 당연히 이 질문들에 국한 되지 않아도 된다. 참고로 몰입과 비판 과정은 동시에 해도 되고 순차적으로 해도 된다.
- How does the person make sense of whatever it is they are discussing?
- In what different ways do they make sense of the topic?
- How ‘commen-sense’ or socially normative is this depiction or story?
- How would I feel if I was in that situation?
- What kind of world is ‘revealed’ through their account?
- What different ways could I make sense of the data?
세 번째는 노트화 (note-making)이다. 이 과정은 familiarization을 언어의 형태로 정리하는 것이다. 노트의 형태는 정말 다양할 수 있다. 종이에 펜으로 끄적이는 걸 수도 있고 잘 정리된 문서일 수도 이다. 이 책에서 나온 예시로는 손으로 그리는 word cloud가 있었다. 본인이 편한 방식으로 정리를 하는 것이 좋다. 이 과정은 다음 단계인 코딩 단계로 넘어가기 전에 데이터 전체와 연구자의 생각을 정리 하는 것이 목적이다. 코딩 과정에서는 개별 데이터를 보긴 하지만 전체 데이터에 대한 구조가 머리속에 대략 있어야 가능한데 노트화 과정에서 그것을 하는 것이다.
Familiarization을 언제 끝내고 다음 단계로 넘어가면 좋은지에 대한 명확한 답은 없다. 본인이 충분하다고 생각하면 넘어가면 된다. 이 단계에 시간을 많이 쓰는 것도 괜찮다. 다만 데이터 셋의 모든 것을 완벽하게 이해할 때 까지 기다릴 필요는 전혀 없다.
Coding: 패턴 찾기
코딩(coding)은 데이터들을 탐색하고 그 속에서 패턴을 찾는 프로세스를 이야기 한다. 그 결과로 코드들을 도출하고 데이터들 마다 코드 라벨을 붙이게 된다. 코드(code)는 코딩 프로세스의 결과물로서 분석적 아이디어나 일부 데이터에 대한 컨셉 또는 의미를 말한다. 코드 라벨(code label)은 코드의 간결한 형태로서 데이터 일부에 할당 된다. 코딩은 유기적이고 진화하는 프로세스이며 틀이 없다. 그렇기 때문에 코드들은 계속적으로 변화한다. 한번에 코드들을 찾는 것이 아니다. 또한 위에서 이야기 한 대로 이 과정은 주관적이며 데이터를 해석하고 그 의미를 만들어 내는 (찾는다는 표현을 일부러 쓰지 않았다) 과정이다. 그렇기 때문에 저자들은 ‘정답’을 찾기 위해서 여러 코더들이 코딩을 하는 것을 추천하지 않는다. 여러 코더들이 같이 코딩을 하는 것은 더 다양한 인사이트를 도출하기 위해서 좋을 수는 있지만 필수적인 것은 아니다. 연구자 한 명이 코딩을 하는 것이 평범한 것이며 어떤 측면에서는 좋을 수 있다고 이야기 한다.
코딩에는 두 가지 접근 방법이 있다. 하나는 귀납적(inductive) 접근이고 다른 하나는 연역적(deductive) 접근이다. 귀납적 접근은 데이터로 부터 코드들을 생성하는 방법이다. 하지만 완벽한 귀납적인 방법을 존재할 수 없다. 연구자의 배경이나 지식 수준에 따라서 데이터를 바라보는 관점이 정의되고 그 틀 안에서만 볼 수 있기 때문이다. 그렇다고 해서 귀납적 접근이 불가능하거나 무의미하지는 않다. 코딩 과정에서 점점 넓혀 나가면 된다. 연역적 접근은 연구자나 이론에서 시작하는 접근이다. 코드들을 데이터로부터 도출 하는 것은 귀납적 방법과 비슷 하지만 연구 질문 자체가 이론으로 부터 나오기 때문에 코드들 자체도 이론에 기반을 두게 된다.
코드에는 두 종류가 있다. 하나는 semantic code이고 다른 하나는 latent code 이다. Semantic code는 명확하게 표현되는 코드들이다. 주로 참가자들이 이야기 하는 내용을 담는다. Latent code는 더 내재적인 의미를 담는 코드이다. 이는 연구자로 부터 도출 되는 경우가 많다. 이 두 코드에 대해서 여러 오해들이 있는데 책에서는 아래와 같이 정리 한다.
| 오해 | 답변 |
|---|---|
| 코드는 semantic 이거나 또는 latent이다. | 두 종류의 단계는 이분법적인 것이 아니다. 대부분의 코드는 이 둘 사이의 어딘가에 위치한다. |
| Latent coding이 semantic 보다 더 정교하거나 낫다. | 그렇게 볼 수 없다. Latent coding이 semantic coding보다 더 어려울 수는 있지만 그것이 더 정교하거나 낫다는 것을 의미하지는 않는다. |
| Semantic coding이 latent 보다 더 믿을 만 하다. | 이 오류는 두 가지 가정에서 기인한다. 하나는 연구자가 semantic coding 과정에서 의미를 해석하지 않고 있는 그대로를 표현한다는 것이고 다른 하나는 데이터의 의미를 연구자의 관점으로 해석하는 것은 믿을만 하지 못하다는 가정이다. 하지만 우리는 항상 의미를 해석할 수 밖에 없고 그 과정에서 자신의 의견이나 가치관이 들어가게 된다. 객관성은 코딩의 종류와는 무관하다. |
| Latent coding은 참가자의 무의식에 존재하는 의미를 찾아낼 수 있다. | 이 역시 흔히 발생하는 오류인데 latent의 의미는 드러나지 않는다는 의미이지 무의식과는 무관하다. 다만, 무의식에 대한 분석을 할 수 있는 이론을 배경으로 코딩을 한다면 가능하다. |
| Semantic coding은 참가자의 말을 인용해야 한다. | 꼭 그럴 필요는 없다. Semantic coding은 참가자의 말을 요약하는게 아니라 명백하게 드러나는 아이디어를 표현하는 것이다. |
| 데이터에 없는 단어를 사용 한다면 그것은 latent code이다. | 참가자의 말을 그대로 사용하지 않는다고 해서 latent code가 되는 것은 아니다. 드러나지 않는 아이디어를 표현하는 것이 핵심이지 단어 사용과는 무관하다. |
| Semantic code는 데이터 너머에 있는 이야기를 하면 안된다. | Semantic code도 연구자의 해석이 들어갈 수 있고 그렇기 때문에 연구자의 해석을 통하여 데이터와 연결 되어 있지만 정확히 데이터에 있지 않는 이야기를 할 수 있다. |
책은 코딩에 대해서 세 가지 가이드라인을 제시 한다. 첫째, 단순히 데이터를 복사하지 마라. 코드는 데이터의 의미를 간결하고 함축적으로 담고 있어야 한다. 둘째, 특정 관점을 명시하라. 좋은 코드 라벨은 지나치게 일반적이면 안된다. 예를 들어서 ‘선택’이라는 코드 라벨 보다는 ‘선택은 중요하다’와 같은 라벨이 더 좋다. 셋째, 코드 라벨에 자신의 의견을 담아야 한다. 앞의 예를 이어서 사용 하자면, ‘선택 하는 것이 궁극적으로 중요하다’와 같은 라벨은 분석하는 사람의 의견이 포함되는 것이다. 이러한 라벨이 더 좋은 라벨이라고 할 수 있다.
코딩은 한번에 끝이 나는 과정이 아니다. 너무 낮은 레벨의 코드가 있거나 너무 높은 레벨의 코드가 있으면 이들의 레벨을 조정하는 과정도 필요하다. 또한 놓치는 코드들이 있을 수 도 있다. 그렇기 때문에 책에서는 적어도 두 번의 코딩 과정을 거치라고 이야기 한다. 데이터의 순서를 섞는 것도 추천 한다. 만약 20개의 데이터가 있다고 하면 첫 번째 코딩 세션에서는 1번 데이터부터 시작하고, 두 번때 코딩 세션에서는 10번째 부터 시작 하는 것이다.
코딩은 사실 끝이 없는 작업이다. 데이터에서 도출 할 수 있는 의미의 한계라는 것이 존재 하지 않기 때문이다. 하지만 우리는 언젠가는 멈춰야 한다. 코딩을 멈춰도 되는 시점은 연구자 스스로가 충분하다고 느끼는 시점이다. 이것을 판단하기 위해 스스로에게 ‘당장 모든 데이터를 잃어버려도 괜찮을까?’ 라고 물어보는 것이 도움이 된다. 코드 라벨들이 데이터가 가지고 있던 모든 의미를 담고 있어야 하고, 그 수준이 된다면 코딩을 멈춰도 좋을 것이다.
Generating initial themes: 테마 찾기
코딩이 마무리 되었다면 코드들을 통해서 테마를 찾아야 한다. 테마를 찾는 것은 데이터에서 패턴을 찾는 것이다. 그렇기 때문에 한 명의 참가자에서만 발견되는 코드는 테마의 재료가 될 수 없다. 그런 데이터가 중요하지 않다는 것은 아니고 TA에서 찾는 테마와는 맞지 않는다는 것이다. 테마를 찾는 좋은 방법 중 하나는 코드들을 흩뿌려 놓고 다시 그룹핑 해보는 것이다. 이런 과정을 하다 보면 어떤 코드들은 그 자체로 테마가 될 것 같다는 생각을 할 수 있다. 그것도 가능하다. 책에서 강조하는 것은 이러한 중간 단계들이 꼭 거쳐야 하는 규칙이 아니라는 것이다.
책에서는 시각적 다이어그램을 활용하는 것이 도움이 된다고 이야기 한다. 잠재적 테마들과 서브 테마들의 관계를 thematic map으로 표현하는 것이다. 아래는 thematic map의 예시이다. Thematic map은 데이터에서 찾아낸 의미들의 패턴, 테마들간의 잠재적 연결과 단절을 파악하는데 도움이 된다.
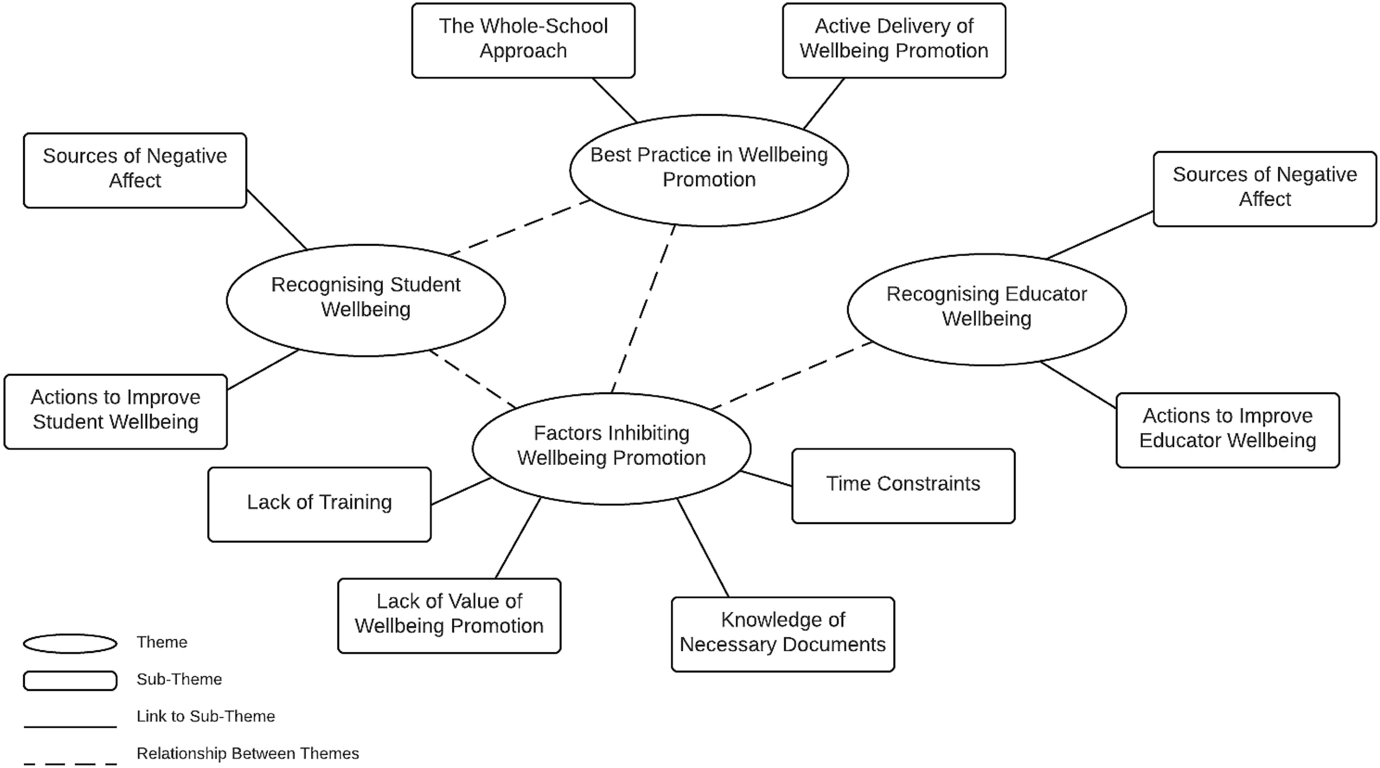 출처: Springer - Quality & Quantity (doi:10.1007/s11135-021-01182-y)
출처: Springer - Quality & Quantity (doi:10.1007/s11135-021-01182-y)
TA 과정에서 세 단계의 테마를 만들게 될 수 있다고 책은 이야기 한다. 가장 상위 레벨의 테마는 overreaching theme이다. 이 테마는 여러 테마들을 포괄하는 하나의 테마이다. 하지만 reflexive TA에서 overreaching theme을 도출 하는 것이 보편적이지는 않고 해야 하는 것도 아니다. 테마(theme)는 다면적인 하나의 컨셉을 의미하며 relexive TA에서 가장 중요한 결과의 단위이다. 서브 테마(subtheme)는 테마 아래에 있는 개념이며 테마의 특정 부분만을 조명한다.
초기 테마를 형성함에 있어서 중요한 다섯가지 포인트가 있다. 첫째, 데이터의 모든 내용을 담을 필요는 없다. 이는 최종 결과물도 마찬가지다. TA는 연구 질문에 답을 하기 위한 이야기를 만드는 과정이지 데이터셋의 모든것을 표현하는 것이 목적이 아니다. 둘째, 테마는 체계적인 중심 컨셉이 있어야 한다. 테마와 데이터의 관계를 민들래 씨앗에 비유 할 수 있다. 개별 민들래의 씨앗들은 날라갈 수 있지만 중심에 있는 꽃 부분에 묶여 있다. 이와 같이 테마 역시 개별 데이터 아이템들에 대한 내용을 모두 담고 있을 필요는 없지만 이들을 하나로 묶을 수 있는 개념이어야 한다. 셋째, 이 단계의 테마들에 너무 얽매이지 않아야 한다. 이 단계에서 도출된 테마들은 후보군들이지 최종적인 것들이 아니다. 넷째, 최종적으로 도출할 테마들에 비해서 더 많은 수의 테마들이 있어도 괜찮다. 이 단계에서 너무 테마의 갯수를 줄이려고 노력할 필요는 없다. 다섯째, 코드와 데이터를 질문과 답변으로 바라보지 않아야 한다. 코드들의 클러스터를 만들면서 특정 질문에 대한 답을 목적으로 하면 안된다. 예를 들어서 ‘왜 사람들은 아이를 낳지 않는가?’와 같은 질문에 대한 답을 하는 코드들을 모으는 것을 피하라는 말이다. 이러한 과정은 전체 데이터셋에 존재하는 패턴을 파악하는 것을 방해하고 명백하게 보이지는 않지만 최종적으로는 유용하고 중요할 수 있는 인사이트를 놓치게 만든다.
몇 개의 테마가 적절한 갯수의 테마인지 궁금할 수 있다. 이 역시 정해진 것은 없지만, 초기 테마의 수가 너무 많은 경우에는 연결성이 없는 분석으로 이어지거나 이후 개선 과정에서 어려움을 겪을 수 있다. 그렇기 때문에 테마의 숫자가 너무 많다고 생각이 되면 줄이려는 노력을 하는 것은 필요할 수 있다.
Developing and reviewing themes: 반복하기
이 과정은 초기 테마들을 반복적으로 살펴 보면서 테마들을 개선해 나가는 과정이다. 이 단계에서 첫 단추로는 각 데이터들에 태그 된 코드들이 적절한지 살펴 보는 것이다. 그리고 개별 테마들 마다 과연 이 유효한 테마로 볼 수 있는지 검토 한다. 이 과정에서 유용하게 던져 볼 수 있는 질문들이 있다. 테마들을 다듬는 과정에서 초기에 도출한 테마들이 많이 바뀌는 것은 자연스럽고 당연하다. 위에서 이야기 한 것과 같이 초기 테마들에 너무 얽매여서는 안된다.
- 테마의 경계를 정할 수 있는가?
- 이 테마를 뒷받침 할 수 있는 데이터가 충분히 있는가?
- 테마 안에 속해있는 데이터들이 너무 다양하지 않는가?
- 테마가 중요한 의미를 담고 있는가?
테마들마다 검토를 한다면 전체 데이터셋에 대해서 검토를 하는 과정도 필요하다. 책에서는 이 과정을 강조 하는데, 그 이유는 TA 과정이 연구자를 데이터로 부터 멀어지게 하는 과정이기 때문이다. 테마를 찾는 과정에서는 주로 코드들만을 보면서 만들게 된다. 그러다보면 원래 데이터와 관련성이 떨어지는 테마를 도출하게 될 수도 있다.
하지만 경우에 따라서는 전체 데이터를 사용하지 않고 일부 데이터만을 사용하는 것도 가능하다. 수집된 데이터 중에서 연구 질문에 관련된 질문들만을 가지고 TA를 진행 하는 것도 좋다. 이는 cherry picking과는 다른 개념인데, 연구자가 동의하는 데이터만 취하고 그렇지 않은 데이터는 무시하는 것이 아니기 때문이다.
테마들을 다듬다 보면 모순되는 지점들을 발견 할 수 있다. 상반된 의견을 이야기 하는 데이터들이 있을 수 있기 때문이다. 이런 경우에 테마들이 상반된 내용을 담고 있어도 될까? 일단, 하나의 테마 안에서는 상반된 의미를 담고 있어서는 안된다. 다만, 상반된 의미를 가지는 테마들이 존재할 수는 있다. 또한, 모순 자체가 연구의 대상이 되는 경우에는 모순에 대한 내용을 담고 있는 테마들이 존재할 수 있다.
Refining, defining and naming themes: 완성하기
이 과정 역시 사실상 테마를 도출하는 반복적인 과정이다. 마무리 작업이라고 보면 된다. 이 단계에서는 theme definition을 작성 하면서 적절한 테마를 도출 했는지 확인 한다. Theme definition은 하나의 테마를 명료하게 설명하는 몇 개의 문장이다. Theme definition을 잘 작성 할 수 있다면 테마를 잘 도출했다고 볼 수 있다. Theme definition을 작성하면서 어려움이 있다면 테마를 다듬는 과정을 더 해야 할 것이다. Theme definition이 아래 질문들을 답을 한다면 잘 작성 되었다고 볼 수 있다.
- 테마가 무엇에 관한 것인가?
- 테마의 경계는 무엇인가?
- 테마의 유일하고 특징적인것이 무엇인가?
- 각 테마가 전체 분석에 어떻게 기여 하는가?
마지막으로 테마의 이름을 지어야 한다. 이름을 짓는 것은 생각보다 중요한 일이다. 왜냐면 테마의 이름을 통해서 독자가 직관적으로 테마를 이해 할 수 있어야 하고, 이름을 잘못 짓는다면 테마를 잘못 이해 할 수 있기 때문이다.
Writing: 분석의 마지막 단계
분석의 결과를 작성하는 것은 분석과 별개의 과정이 아니라 분석의 일부분이다. 때문에 글로 작성하지 않는다면 분석이 완료 되었다고 볼 수 없다. 글을 쓰는 과정에서도 분석이 계속 이루어지게 된다. 이것은 분석이 덜 되어서 발생하는 현상이 아니라 정성적 분석 방법론의 특징이다. 보통 정량적인 분석의 경우 결과를 도출하고 나서 그것을 글의 형태로 정리할 뿐이고, 분석은 글을 쓰는 과정에서 일어나지 않는다. 하지만 정량 분석의 경우 분석 결과를 정리하며 전체 이야기를 만드는 과정에서 분석이 계속 일어나게 된다. 나는 이 이유가 정량 분석의 결과물 자체가 이야기이기 때문이라고 생각 한다.
논문 또는 리포트에 들어가야 하는 내용은 기본적인 내용들이 일단 필요하다. 동기와 배경을 설명하기 위한 introduction과 literature review가 필요하고 연구에서 사용한 방법(method or methodology)을 설명 해야 한다. 이 부분에서 왜 TA를 사용 했는지 정당성을 설명 하는 것이 좋다. 단순하게 남들이 많이 사용 하는 방법이라거나 데이터에서 패턴을 찾기 위해서와 같은 설명은 설득력이 부족하다. 특정 연구에서 어떤 목적이 있었기 때문에 TA가 적합하다는 이야기를 하는 것이 좋다. 그리고 실제로 어떻게 데이터를 수집 했는지 자세하게 설명 해야 한다. 마지막으로는 결과와 논의점을 (results and discussion) 기술 한다. 이 부분도 구조적으로 접근하는 것이 좋다. 처음에는 도출한 테마들에 대해서 전반적인 설명을 기술하고 그 뒤에 각 테마들에 대해서 설명하는 것이 좋다. 테마에 대해 설명을 할 때는 연구자의 생각을 기술하는 부분도 있어야 하고 데이터의 일부를 인용하는 것도 필요하다. 인용을 할 때는 생생한 예시를 사용하는 것이 좋고, 지나치게 특정 참가자의 데이터만 사용 하는 것은 피하는 것이 좋다. 같은 데이터를 반복해서 인용 하는 것도 피하는 것이 좋고 불필요한 세부 사항은 제거 하는 것이 좋다. 인용을 이해하는데 맥락이 필요하다면 명확하게 같이 제시 해야 한다.
인용을 하는 목적은 크게 두 가지가 있다. 하나는 묘사를 위한 목적이다. 테마가 어떤 내용을 담고 있는지 구체적인 사례를 보여주면서 설명하는 것이다. 또 다른 목적은 분석이다. 인용의 특정 부분을 시작으로 해서 연구자의 분석적 주장을 뒷받침하는 것이다. 즉, 테마 자체를 묘사 한다기 보다는 분석의 과정을 묘사하는 것이라고 볼 수 있다.
분석 결과를 기술함에 있어서도 다양한 실수를 할 수 있다. 흔히 하는 실수들로는 다음과 같은 것이 있다. 첫째, 데이터를 의역(paraphrase)하는 것이다. 이것은 분석이 아니라 데이터를 그냥 다르게 표현하는 것 뿐이다. 둘째, 인용만 하고 데이터를 분석하지 않는 것이다. 셋째, 데이터와 싸우는 것이다. 데이터를 분석하지 않고 왜 데이터 혹은 참가자가 틀렸는지에 대해서 설명하는 경우이다. 넷째, 인용한 데이터가 분석에서 주장하는 바와 일치하지 않는 것이다.
한 가지 궁금할 수 있는 것이, 분석 결과를 일반화 할 수 있는지를 설명해야 하는가 이다. 일반화라는 것은 연구의 결과가 연구에 참여한 샘플 집단 뿐만 아니라 그 외에 대상에도 해당 되는 것을 의미한다. 적은 샘플을 대상으로 한 정량 연구들은 일반화 문제에 시달리곤 한다. 또한 통계적인 분석을 하는 것이 아니기 때문에 객관적인 일반화의 근거를 제시하기 어렵기도 하다. 이러한 고민은 정량 연구를 하는 사람들이라면 한번 씩 했을 것 같다. 하지만 책에서도 이에 대해서는 명확한 가이드라인을 제시하지는 않는다. 다만, 일반화 가능한 결과라는 것을 설득하는 것은 필요하고 책에 다양한 예시들을 보여준다. 내가 이해하기로는 대체로 분석 결과가 도출 된 일반화 가능한 맥락을 도출하고 이 맥락이 일반적이라는 접근을 하는 것 같다.
마치며
TA는 정성 연구에서 많이 사용하는 방법론이다. 위에서 언급한 책의 저자들이 쓴 논문은 이 글을 쓰는 당시 20만회가 넘게 인용이 되었다. 하지만 나와 같이 공학 분야에서 공부를 했거나 정량적인 분석에 익숙한 사람에게는 어렵게 느껴질 수 있다. TA는 정해진 프로세스가 아니라 연구 방법이기 때문에 연구자 마음대로 해도 될 것 처럼 느껴진다. 하지만 사실은 그렇지 않고 잘못 사용하기 쉽기에 수행하는데 어려움이 많이 있을 수 있다. 나는 제대로 TA를 수행한 경험이 없는데 그것은 TA에 대한 공부가 부족해서 막연한 두려움이 있었고 박사 과정에서 TA가 필요한 연구를 하지 않았기 때문이기도 하다. 하지만 회사에서 일을 하면서 이 필요성에 대해서 더 많이 느끼고 있다. 책을 읽고 정리하면서 내가 잘못 알고 있던 부분들이 있다는 것을 깨닿고 배우게 되었다. 앞으로 내가 정량연구를 함에 있어서 많은 도움이 될 것이라 생각 한다.