소프트웨어 제품에서 A/B 테스트 디자인하고 결과를 분석 하는 것이 중요하다는 이야기는 여러 곳에서 들어 봤을 것이다. 나 역시 대학원에서 연구를 하면서 실험의 중요성에 대해서는 이해하고 있었지만 A/B 테스트라는 것에 대해서 정확히 공부를 해 본적은 없다. 그래서 흔히 사람들이 이야기는 A/B 테스트는 무엇인지 알아보고 Human-Computer Interaction (HCI) 에서 사용하는 실험 방법론과 어떤 차이가 있는지 궁금했다. 이 글은 내가 아래 논문과 책을 읽고 중요한 내용들만 간추려서 정리 한 것이다. 그리고 나의 생각도 중간 중간 덧붙인다.
- Kohavi, Ron, Randal M. Henne, and Dan Sommerfield. “Practical guide to controlled experiments on the web: listen to your customers not to the hippo.” Proceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining. 2007.
- A/B 테스트 [신뢰할 수 있는 온라인 종합 대조 실험]
첫 불릿에 있는 논문은 두 번째 불릿에 있는 책의 저자들이 쓴 논문이다. 그래서 책을 읽기 부담 된다면 논문만 읽어 보는 것이 도움이 될 것이다. 중요한 내용들은 논문에 다 있다고 생각한다. 이 글 역시 논문의 내용을 먼저 정리하고 뒷 부분에 논문에서 적게 다루지만 책에는 자세히 나오는 내용을 약간 덧붙인다.
A/B 테스트와 관련해서는 너무나도 많은 자료들이 있어서 내가 인터넷에 관련한 이야기를 올리는 것이 의미가 있나 싶지만 누군가에게는 내가 이해하는 방식이 도움이 될 수 있기에 정리해서 올려 본다. 참고로 위 논문에는 명언이 많이 나온다. 이 글에서 인용하는 명언들은 모두 논문에 있는 것들이다.
A/B 테스트란 무엇인가?
A/B 테스트는 쉽게 이야기 해서 1) 어떤 집단의 사람들을 A와 B로 일컬어지는 두 조건에 노출하고 2) 그 결과를 측정하고 비교하여 두 조건들 중 어느 조건이 더 좋은지 판한다는 실험 방법이다. 여기에서 집단에 있는 모든 사람들을 두 조건에 모두 노출시키거나 (within subject design) 반으로 갈라서 한쪽은 A 조건, 다른 쪽은 B 조건에 노출 시킬 수 있는데 (between subject design) 온라인 서비스에서 이야기 하는 A/B 테스트는 주로 between subject design을 이야기 한다.
그럼 A/B 테스트는 왜 유용할까? 아래 명언이 그에 대답을 대신한다. 우리가 어떤 가설을 가지고 탁상공론을 하는 것 보다 실제로 실험을 한 후 결과를 보는 것이 훨씬 가설 검증에 효과적이기 때문이다.
One accurate measurement is worth more than a thousand expert opinions - Admiral Grace Hopper
논문에는 괴혈병 예시가 나온다. 1700년대 영국 선박의 선장은 선원들에게서 괴혈병이 발생하는 것을 발견 했다. 선장은 보급품에 있던 감귤류가 연관이 있다고 생각하고 한 가지 실험을 해보기로 했다. 절반의 선원에게는 식단에 라임을 주고 (Treatment, 실험군), 절반의 선원에게는 주지 않았다 (Control, 대조군). 실험군에서 괴혈병이 덜 발생하는 것을 확인 하였고, 당시에는 비타민 C가 괴혈병과 관련이 있다는 것을 몰랐지만, 그 이후로 선박에는 꼭 감귤류 식단이 포함 되었다고 한다.
비슷한 일이 온라인 서비스에도 있었다. 약 300년 뒤, 아마존 (회사) 에서 Greg Linden은 쇼핑카트에서 추천 상품을 보여주는 프로토타입을 만들었다. 마케팅 팀의 VP는 극구 반대 했다. 사람들이 체크아웃을 하기 전에 방해 받을 것이라는 것이 이유 였다. 그는 대조 실험을 진행 하였고 매우 큰 차이로 추천 상품을 보여주는 인터페이스가 더 많은 매출로 이어졌다. 이제는 대부분의 마켓에서 이러한 인터페이스를 사용한다고 한다.
한 가지 강조하고 싶은 것이 있는데 A/B 테스트는 대조 실험, 영어로는 controlled experiment라는 것이다. 우리가 관찰하고자 하는 변인 빼고 다른 조건들은 모두 동등하도록 ‘컨트롤’ 해야 한다. 이 실험 방법은 가설을 검증할 수 있는 가장 확실한 방법들 중 하나이다. 약의 효과를 검증 하거나 인터페이스의 효용성을 검증 할 때도 사용 된다.
그럼 컨트롤되지 않은 환경에서 하는 실험도 있을까? 있다. 컨트롤 되지 않은 환경에서 취득한 데이터를 이용하는 방법으로는 post-hoc analysis, interrupted time series (quasi experiment) 등이 있다. Post-hoc analysis는 수집 된 데이터를 이미 사건이 일어난 후에 분석 하는 방법이다. 인구 통계 데이터를 가지고 집단별 분석을 하는 것이 예시이다. Interrupted time series는 특정 시점에 변화를 주고 예측값과 관찰 값의 차이를 통해 가설을 검증하는 방법이다. 이 방법이 quasi experiment인 이유는 실험군과 대조군을 랜덤하게 할당 하지 않기 때문이다. 대조 실험은 관찰하려는 요소 이외의 다른 요소들을 모두 균등하게 분포 시키므로서 변인 외의 요소들이 관측값에 영향을 미치지 못하게 하는데 quasi experiment는 이것이 불가능하다. 왜냐면 시간의 흐름에 따라서 샘플링을 하게 되면 시간에 영향을 받는 요소에 대해서는 랜덤으로 샘플링을 하는 것이 아니게 되기 때문이다. 이 방법들은 변인의 효과를 정확하게 볼 수는 없지만 대조 실험이 불가능 한 경우에는 유용하게 사용 할 수 있다. 예를 들어 역사적 사건에 따른 연구를 한다면 대조실험이 불가능하다.
A/B 테스트 디자인 하기
A/B 테스트의 구조는 아래 그림에 나와 있다. 연구를 하고자 하는 대상이 있으면 대상을 절반씩 나누어서 한쪽은 실험군, 다른 한쪽은 대조군에 할당하고 각각 다른 조건에 노출 시킨다. 이 과정에서 핵심은 대상을 두 집단에 랜덤하게 배정하는 것이다. 사용자 할당에 편향이 생기면 결과에도 편향이 생긴다. 그리고 Overall Evaluation Criterion (OEC) 가 각 집단에 대해서 측정 된다. OEC는 종속변수라고 생각 하면 된다. 온라인 서비스에서는 주로 클릭률이나 전환률등의 지표가 된다. 이렇게 실험을 디자인 했을 때 실험군과 대조군에서 OEC의 차이가 생긴다면 두 집단을 나눈 요소가 OEC 변화의 원인이 된다.
 출처:
출처: A/B 테스트를 이해하기 위해서는 중요한 개념들이 있는데 간단하게 불릿으로 정리하겠다.
| 용어 | 설명 |
|---|---|
| Overall Evaluation Criterion (OEC) | 측정 가능한 실험의 수치적 목표다. 종속변수(dependant variable)와 같은 말이다. 논문에서는 OEC는 하나로 설정하는 것을 추천한다. 여러 변수를 관찰하고자 한다면 weighted sum을 통해 하나의 OEC를 만드는 것이 좋다. |
| Factor | 실험의 변수(variable)를 의미한다. 단순한 A/B 테스트의 경우 하나의 요소 (factor)가 두개의 값 (A,B)를 갖는다. |
| Variant | 변화된 대상을 말한다. 대조군 혹은 실험군이다. |
| Experimentation Unit | 실험 대상의 단위를 뜻한다. 보통은 한 명의 유저가 되는데 경우에 따라서는 세션 및 페이지 방문이 될 수 도 있다. |
| Null Hypothesis (귀무 가설) | Variant 별 OEC의 차이가 없을 것이다 라는 가설이다. 일반적으로 대조 실험은 귀무 가설을 채택 하느냐, 버리느냐를 결정 하는 것으로 요소의 효과를 판단 한다. |
| Confidence Level | 귀무 가설이 참이라고 할 때 귀무 가설을 채택 할 확률이다. 일반적으로 95%. 중요한 점은, 귀무가설이 참이라고 해도 귀무 가설을 거절 할 확률이 0이 아니라는 점이다. |
| Power | 귀무 가설이 거짓이라고 할 때 귀무 가설을 거절 할 확률이다. Power는 실험이 얼마나 작은 차이를 감지 할 수 있는지를 의미한다. |
| A/A Test | Null Test라고도 부른다. 실험 시스템을 검증하기 위해서 수행 한다. 실험군과 대조군을 같은 variant에 노출 시켰을 때 OEC의 차이가 없는지를 확인하는 실험이다. 만약 차이가 있다면 실험 시스템이 사용자를 랜덤하게 배치하지 못한다는 것을 뜻한다. |
| Standard Deviation | 표준 편차. 데이터가 얼마나 분산 되어 있는지를 의미 한다. |
| Standard Error | 샘플링 한 확률 분포의 표준 편차. 쉽게 이야기 하면 표본 집단의 평균이 모집단에 비해서 얼마나 벗어날 수 있는지를 의미한다. 샘플이 많을 수록 에러는 작아진다. 표준 편차와 표준 에러의 차이를 더 알고 싶으면 이 영상을 참고 하면 좋다. |
결과 분석하기
위와 같이 테스트를 디자인 하고 수행 했다. 그러면 두 집단에서 측정한 OEC를 얻게 되는데 이 것이 차이가 있는지 없는지 어떻게 알 수 있을까? 단순히 평균이 높고 낮음으로 평가를 할까? 그것 보다는 좀 더 엄밀한 방법이 있다. 흔히 이걸 Null Hypothesis Significance Testing (NHST) 라고 한다. 귀무 가설을 우리가 채택을 할지 말지 결정을 하는 것이다. 만약 귀무 가설을 채택 한다고 하면, 두 조건이 차이가 없다는 것이고 채택하지 않으면 차이가 있다고 판단 하는 것이다.
귀무가설의 채택과 거절은 다음과 같은 기준으로 한다.
- 종속 변수를 정한다.
- 집단별 종속 변수가 차이가 없다는 귀무 가설을 세운다.
- 두 집단의 측정한 종속 변수를 가지고 p 값을 계산 한다.
- p 값이 기준보다 낮으면 (주로 5%) 귀무 가설을 거절한다.
여기서 p 값은 p 값은 귀무 가설이 참이라고 할 때 측정된 종속 변수들이 나올 가능성을 의미한다. p가 5%보다 낮다는 것은 그만큼 가설이 참인 경우 측정 값들이 나오기 어렵기 때문에 참이 아닐 확률이 높고 그래서 거절 한다는 논리이다.
효율적인 테스트 디자인 하기
여기까지 알고 나면 총 몇 명을 대상으로 실험을 하는게 좋을지 궁금할 것이다. 최대한 적은 사람에게 실험을 해서 의미있는 결과를 뽑아내고 싶을 것이다. 그것이 효율적인 방법이기 때문이다.
일단 의미있는 결과가 잘 나오는 실험을 디자인 하는 방법에 대해서 이야기 해보겠다. 결과가 잘 나온다는 것은 두 집단의 작은 차이라도 잘 잡아내는 실험을 의미한다. 이는 위에서 이야기 한 파워와 이 있다. 파워가 높은 실험일 수록 검정력이 높아진다. 파워를 높이는 방법은 표준 오차를 줄이는 것인데 표준 오차를 줄이는 방법은 다음과 같다.
- 샘플 수를 늘려라.
- 편차가 작은 OEC를 사용해라. 예를 들어서 전환률 (0-100%)은 구매 여부 (0/1) 보다 편차가 클 수 밖에 없다.
- variant에 노출 된 사용자들만 통계에 포함 시키므로서 OEC의 편차를 줄여라. 이 사실을 생각보다 자주 간과 하게 되는데 뒤에 좀 더 자세히 설명하겠다.
즉, 샘플의 크기는 실험을 통해서 얼마나 작은 차이까지 잡아내고 싶은가에 따라 달라진다. 작은 차이까지 보고 싶으면 샘플의 수가 커지고, 그렇지 않으면 샘플의 수가 작아도 된다. 아래 식은 적절한 샘플 사이즈를 계산 할 수 있는 식이다.
𝑛 = (4𝑟𝜎/Δ)^2
- 𝑛 : 샘플 사이즈.
- 𝑟: variant 갯수. variant 별로 균등하게 샘플이 분배 된다고 가정. A/B 테스트라면 2이다.
- 𝜎: 표준 편차.
- Δ: (원하는) OEC의 최소 차이.
샘플 사이즈 계산의 예시이다. 실험 기간동안 5%의 사람들이 우리 홈페이지에서 구매를 했다고 하자. 구매 한 사람은 평균 75$를 썼다. 그러면 전체 평균 지출 금액은 3.75$이다. 95%는 0$를 썼기 때문이다. 표준 편차가 30$이라고 가정 하자. 기존의 인터페이스를 A라고 하고 새로운 인터페이스를 B라고 할 때 B가 기존 매출의 5% 이상의 변화를 가져 오는지 판단 하고자 한다. 여기에 필요한 샘플 수는 다음과 같다.
n = (4 * 2 * 30 / (3.75 * 0.05))^2 = 160만명
엄청나게 많다. 스타트업에서 160만명을 대상으로 테스트 하는 것은 터무니 없다. 필요한 샘플 수를 줄이고 싶다. 만약 매출이 아니라 conversion rate (구매 전환률)에 관심이 있다고 해보자. 그럼 전환률을 OEC로 잡는다. 전환률이 5% 이상 차이가 나는지 본다고 하자. 전환은 구매 했거나 / 하지 않았거나 두 가지 결과만 존재 하기 때문에 Bernoulli 분포를 따르고 Bernoulli 분포의 표준 편차는 sqrt(p*(1-p)) 이다. 이렇게 계산하면 약 50만명으로 샘플 수는 줄어든다. 참고로 아래 식에서 분모가 0.05 * 0.05인 이유는 전환율이 5%인데 5%의 차이를 감지하고 싶어서 그런 것이다.
(4 * 2 * sqrt(0.05 * 0.95) / (0.05 * 0.05))^2 = 50만명
샘플수를 더 줄이고 싶다. “variant에 노출 된 사용자들만 통계에 포함 시키므로서 OEC의 편차를 줄여라.”라는 말 처럼 대상자를 variant에 노출 된 사람으로 한정하면 샘플수를 줄일 수 있다. 위 예시에서 구매는 체크아웃 페이지까지 도달 한 사람들만 가능하다. 즉, 전체 홈페이지 방문자가 아니라 체크 아웃에 도달한 사람들만 고려 해보자. 만약 전체 사용자 중 10%가 체크아웃까지 오고, 체크아웃에서는 50%의 사용자가 최종 구매를 한다고 하자. 그러면 전환율이 5%가 아니라 50%가 되고, 5%의 차이를 검정 한다고 하면 표준 편차가 0.5로 증가 하여 필요한 샘플 수가 25만 6천명으로 절반 정도 줄어든다.
(4 * 2 * sqrt(0.5 * 0.5) / (0.5 * 0.05))^2 = 25.6만명
논문에 나온 예시 말고 좀 더 현실적인 예시를 생각해 보자. 목표하는 power를 달성 할 수 있는 참가자를 모집하면 좋겠지만 다수의 서비스는 몇 십 만명의 사용자가 없다. 그래서 현실적으로는 우리가 모을 수 있는 사람들을 대상으로 A/B 테스트를 했을 때 어느 정도의 power를 가지는지 알아보는 것이 유용하다. 이는 n을 가지고 검정력을 계산하는 것이다. 어떤 회사가 인스타그램으로 광고를 집행 한다고 하자. 1주일에 2000명에게 광고가 노출 된다. 여기에서 평균 5% 정도만 최종 클릭을 한다. 그러면 우리는 A/B 테스트로 최소 몇 %의 광고 클릭률 차이를 확인 할 수 있을까? 식은 아래와 같고, 계산해 보면 0.78이 나온다. 이는 대조군이 평균적인 결과를 보일 때 실험군이 대략 78% 이상 좋지 않으면 차이가 없다고 나온다는 의미이다. 정확하지는 않은 해석인데 대략적으로 실험에서 두 조건이 어느 정도의 차이를 가지고 있어야 유의미한 차이가 측정 될지 감을 잡기에는 유용하다. 예를 들어서 2000명을 대상으로 실험을 하는데 실험 설계자가 보기에도 영향력이 작은 변인을 대상으로 실험 하는 것은 무의미 할 수 있다. 이렇게 보면 정밀한 A/B를 위해서는 꽤나 많은 샘플이 필요하다는 것을 알 수 있다.
Δ = 4𝑟𝜎/sqrt(𝑛) = 42sqrt(0.05 * 0.95) / sqrt(2000) = 0.039 = 0.05 * q
q (검정 가능 차이 비율) = 78%
A/B 테스트의 한계 및 주의사항
A/B 테스트도 분명 한계가 있다. 먼저 논문에서 이야기 하는 네 가지 한계 및 주의사항에 대해서 이야기 하겠다.
첫 번째로 결과의 이유를 알려주지는 않는다. 왜 어떤 효과가 있는지는 설명 할 수 없다. 이것은 정성적인 분석을 통해서 알아 내야 한다.
두 번째로 단기적인 성과와 장기적인 성과 사이의 밸런스가 필요하다. 예를 들어서 검색 엔진의 광고 매출을 늘리기 위한 알고리즘을 설계 한다고 해보자. 단기적으로는 검색 성능이 떨어질 수록 매출이 오른다. 왜냐면 사람들이 원하는 답을 찾지 못해서 쿼리를 더 많이 날리기 때문이다. 하지만 장기적으로 보면 고객들이 떠나기 때문에 좋지 않다.
세 번째로 primacy effect and newness (novice) effect를 고려해야 한다. 새로운 기능에 대해서는 사용자들이 신기하거나 궁금해서 더 많이 사용 할 수도 있고 (novice effect) 익숙한것이 좋아서 더 사용하지 않을 수 있다 (primacy effect).
마지막으로 parallel Experiment 효과가 발생 할 수 있다. 이론적으로는 실험 여러개를 동시에 수행 할 때 실험들 간에 영향 (인터랙션)이 생길 수 도 있다. 하지만 저자들에 의하면 생각보다 여러개의 실험을 동시에 돌려도 실험 간의 영향이 잘 발생하지 않는다고 한다.
지금까지는 논문에 대한 내용들이 주였는데 이제는 부터는 책의 내용들을 이야기 해보겠다. 책에서는 A/B 테스트를 하면서 특히 주의해야 하는 것들에 대해서 좀 더 자세히 나온다.
트위먼의 법칙과 실험의 신뢰도: 통계 결과의 잘못된 해석
트위먼의 법칙: “흥미롭게 보이거나 다르게 보이는 모든 것들은 대체로 틀렸다.” - A.S.C Ehrenberg
우리는 여러가지 이유로 통계 결과를 잘못 해석 할 수 있다. 특히 p 값의 의미를 잘못 해석 하는 경우가 있는데 아래는 흔히 하는 실수들이다.
| 잘못된 해석 | 잘못된 이유 |
|---|---|
| p=0.05이면 귀무 가설이 참일 확률이 5%에 불과하다 | p값은 귀무가설이 참이라는 가정을 가지고 계산 한다. 참일 확률을 이야기 하지 못한다. |
| 유의하지 않은 차이 (p>0.05) 는 그룹간에 차이가 없음을 의미한다. | 샘플 수가 부족해서 검정력이 부족하다는 의미일 수도 있다. |
| p=0.05는 귀무가설 하에 수많은 시행 중 5%만 발생하는 데이터를 관측 했음을 의미한다. | 부정확한 표현이다. p값은 관찰 된 것과 같거나 더 극단적인 값을 얻을 확률이다. |
또한 실험 방법이 잘못되면 잘못된 결과를 얻게 된다. 그 중 하나로 p값 미리보기가 있다. p 값을 모니터링 하면서 사람이 개입하여 적절한 시기에 실험을 중단하는 것을 말한다. 책에 따르면 이러한 경우 5-10배의 편향된 결과를 낸다고 한다. 사람이 개입해서 p값을 기준으로 실험을 중단하면 사람의 의도가 결과에 개입되기 때문이다. 그렇기 때문에 p 값을 계산 하기 전에 미리 실험 기간을 정하고 해야 한다.
같은 실험을 여러번 반복 하는 것도 안된다. 다중 가설 검정이라는 개념인데 변인이 아무런 효과가 없어도 동일한 실험을 20번 하면 우연히 한 번은 통계적 효과가 있다고 나올 수 있다 (1/20 = 0.05). 이는 작지 않은 확률이다. 그래서 별 다른 이유 없이 동일한 실험을 여러번 하면 안된다.
또 다른 잘못된 해석 케이스로 심슨의 역설에 빠지는 경우가 있는데 이것은 세그멘트 별 결과와 전체 합의 결과가 다를 수 있다는 역설이다. 만약 금, 토 이틀에 백만명의 사용자가 있는 홈페이지에서 금요일에는 1%에 실험군을 할당하고 토요일에는 50%에 실험군을 할당 한다고 하자. 아래 그림에서 처럼 금, 토 모두 실험군이 더 좋은 결과를 보여도 총 합을 하면 대조군이 더 좋은 결과를 보이는 것 처럼 보인다.
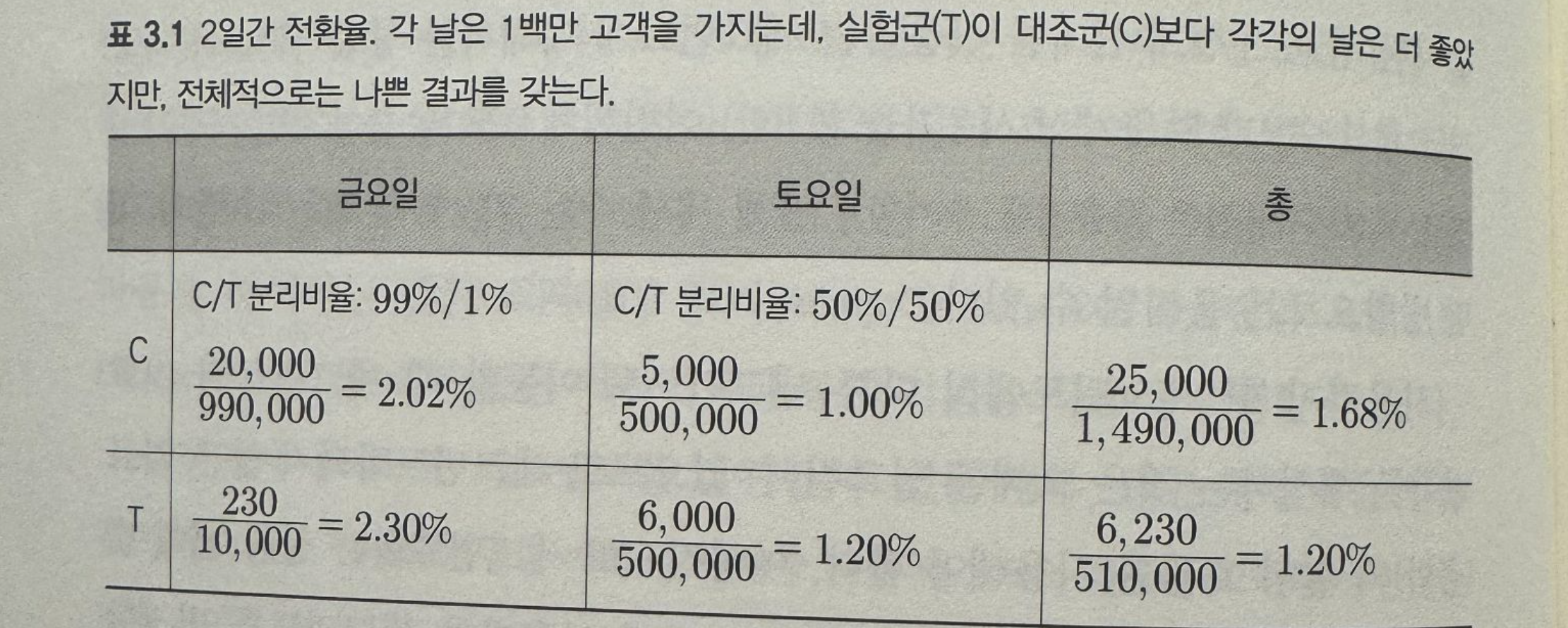 A/B 테스트 [신뢰할 수 있는 온라인 종합 대조 실험]에서 발췌
A/B 테스트 [신뢰할 수 있는 온라인 종합 대조 실험]에서 발췌
샘플 비율 불일치 문제
샘플 비율 불일치 (Sample Ratio Mismatch, SRM)는 실험군과 대조군의 샘플 수가 일치하지 않는 문제를 뜻한다. 즉, 두 조건에 정말 랜덤하게 샘플이 할당 되었는지를 확인 하는 것이다. 다시 말해서 실험군에 노출 시키는 과정에서 편향이 없었는지를 확인하는 작업이다. 예를 들어서 동전을 100번 던진다고 해보자. 앞면이 45번 나오고 뒷면이 55번 나왔다. 동전이 완벽한 대칭이어도 이런 결과가 나올 수 있다. 하지만 혹시나 동전이 한쪽이 찌그러져서 편향된 결과가 나온 것은 아닌지 확인하는 작업이라고 보면 된다.
참고로 이 문제 때문에 온라인에서 광고를 집행하고 A/B 테스트를 돌리면 안된다. 왜냐면 요즘 온라인 광고는 대부분 타겟 광고라서 랜덤이라고 보기 어렵다. 메타와 같은 플랫폼에서 광고를 돌리면 알고리즘 때문에 소재별로 정확하게 랜덤하게 샘플을 할당한다는 보장이 없고 실제로 결과를 보면 샘플 비율이 다르게 나오는 경우가 많다. 메타에서 제공하는 A/B 테스트 기능이 있는데 이것도 내부적으로 정확하게 어떻게 돌아가는지 알기 어렵다. A/B 테스트 기능을 쓰는 경우에는 그냥 거기에서 제공하는 결과를 믿는수 밖에 없다.
그럼 SRM의 유무는 어떻게 판단 할까? SRM은 두 집단의 샘플 비율을 표준 t-검정이나 카이 제곱 검정을 사용해서 판단 할 수 있다. 이 과정을 쉽게 설명하면 다음과 같다. 정말 랜덤하게 샘플링을 한다면 집단의 비율이 1:1이 되어야 한다. 두 집단의 비율이 1.0에 비해서 통계적으로 유의미하게 벗어 나 있는지 확인한다. 예를 들어서 대조군에 821,588 명, 실험군에 815,482명이 할당 되었다고 하자. 카이 제곱 검정을 하면 p 값이 1.8E-6 이므로 가설이 기각 된다. 즉, 랜덤하게 샘플링 되지 않았기 때문에 이 실험의 신뢰도는 하락한다. 이러한 이유로 A/B 테스팅을 한다면 내 샘플이 꼭 SRM이 있는지 없는지를 확인 하는 것이 좋다.
SRM 검정까지 포함하여 간단하게 A/B 테스트 결과를 분석할 수 있는 툴을 구글 스프레드시트로 만들었다. 필요한 사람은 가져다가 활용 해도 좋고 오류가 리포트되면 업데이트 할 계획이다.
A/B 테스트만으로 뛰어난 제품을 만들 수 있나?
여기서 부터는 나의 생각이다. 결론적으로 이야기 하면 나는 A/B 테스트만으로 뛰어난 제품을 만들 수 없다고 생각 한다. 나는 A/B 테스트를 아주 날카로운 메스에 비유를 한다. 제품에서 세밀한 부분을 다듬는데 적절하지만 제품의 큰 틀을 잡기에는 부적절하다고 생각 한다. 초기의 제품을 설계할 때는 너무나도 많은 파라메터가 있다. 그런데 제품을 만들면서 모든 파라메터에 대해서 테스트를 하는 것은 굉장히 비효율적이다. 큰 틀은 직관으로 설계해야 하고 세부적인 방향성을 잡아 나가는 과정에서 A/B 테스트가 효과적이라고 생각 한다. 조금 덧붙이자면 직관이라는 것이 내 생각대로만 한다는 이야기가 아니다. 흔히 이렇게 착각하는 것 같다. 직관을 쌓기 위한 과정이 필요하다. 사용자를 면밀히 이해하는 것이 그 중 하나의 방법일 것이다.
위와 비슷한 이야기인데, 적절한 가설을 세울 수 없으면 A/B 테스트는 무용지물이다. 하지만 프로덕트의 틀 조차 없는 상태에서는 엄밀한 가설을 세우기가 매우 어렵다. 예를 들어서 ‘사람들이 사진을 공유하고 좋아요를 누를 수 있는 SNS를 만들면, 해당 서비스의 DAU는 최소 1만명이 될 것이다’와 같은 가설은 잘 생각해 보면 실험이 불가능한 명제라는 것을 알 수 있다. 대조군을 만들 수 없기 때문이다. 나는 Product Market Fit (PMF)를 A/B 테스트로는 찾을 수 없다고 생각 한다.
A/B 테스트는 둘 중 더 나은것을 찾는 것이기 때문에 둘 다 좋지 않은 옵션인 경우에는 이를 알 수가 없다. 이게 치명적인 문제라고 생각하는데 내가 좋은 실험군을 만들 수 있는 능력이 없으면 A/B 테스트를 백번 해도 좋은 프로덕트를 만들 수 없다.
A/B 테스트는 Long-term OEC를 세우고 실험 하기가 어렵다. 좋은 제품은 긴 기간동안 많은 가치를 제공해야 한다. 이것을 실험으로 입증 하려면 긴 시간동안 해야 하는데 이는 쉽지 않다. 많은 리소스가 들고 빠르게 제품이 변하는 초기 스타트업에서는 긴 시간 동안 변인을 완벽하게 통제하기란 쉬운일이 아니다. 길게 엄밀한 대조 실험을 하는 것과 부정확 하더라도 빨리 제품을 업데이트 해서 반응을 보는게 (interrupted time series 케이스가 되겠다.) 더 효과적일 수 있다.
그럼에도 불구하고 A/B 테스트는 중요하다. 메스가 필요한 순간이 있다. A/B 테스팅의 장점과 단점을 명확히 이해하고 필요할 때 정확하게 사용하는 것이 중요하다.
The fewer the facts, the stronger the opinion - Arnold Glasow